Flow Matching 与 DDIM 小记
背景故事
2022 年 10 月左右,同期有三篇关于 Flow 模型用于图像生成的论文发表,并都被 ICLR 2023 录用:
- Flow Matching for Generative Modeling
- Learning to Generate and Transfer Data with Rectified Flow
- Building Normalizing Flows with Stochastic Interpolants
这三篇文章从不同角度出发得推导出了同一个生成模型,下面再整理一下三篇论文的故事讲法。
Flow Matching
背景:连续归一化流
连续归一化流(Continuous Normalizing Flows, CNF)的概念最早由 Chen et al. (2018) 提出,CNF 通过求解常微分方程(ODE)来实现数据的变换。时间依赖的概率密度路径
CNF 可以通过推前操作将先验分布
同时连续性方程可用于验证向量场
CNF 可以用于建模任意的概率路径,然而此前不存在高效的方法 1来学习向量场
再来进一步考虑如何构造可从数据集中采样求得的
类似的,向量场
原文证明了条件向量场
的梯度等价于 FM 损失函数
在图像生成模型中,一般把高斯噪声作为先验分布,即
可以证明此时的条件速度场具有唯一的形式
DDIM 的均值
论文又提出 OT 速度场的设计,使用线性插值的均值
Rectified Flow
背景:传输映射问题
给定
在生成建模中,
最优传输(Optimal Transport, OT)目标希望最小化某个代价函数
其中
Rectified Flow 使用一个简单的 ODE 来学习传输映射
问题转换为学习速度场
对源分布和目标分布中观测到的样本
则
还不能直接用这个 ODE 作为速度场
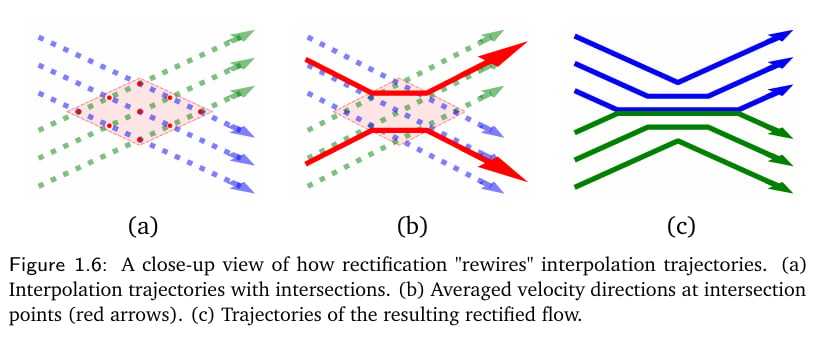
- 不同的插值轨迹
之间可能存在相交点,在同一个 处会有多个可能的 取值,因为不知道要沿哪条轨迹走。 - 另一方面,在 ODE
中, 必须由 唯一确定,于是不同的 轨迹是不能相交的。 - 于是在相交点处,
可以取值为 在所有可能的 取值上的平均值。 - 导致原本的直线轨迹
必须在相交点处弯曲来避免相交,并改变原分布和目标分布的映射关系。
以上 Rectify 过程更新了传输映射
代入线性插值轨迹得到训练目标
此训练目标就可以直接用在代码里了。
Rectify 过程将
Reflow
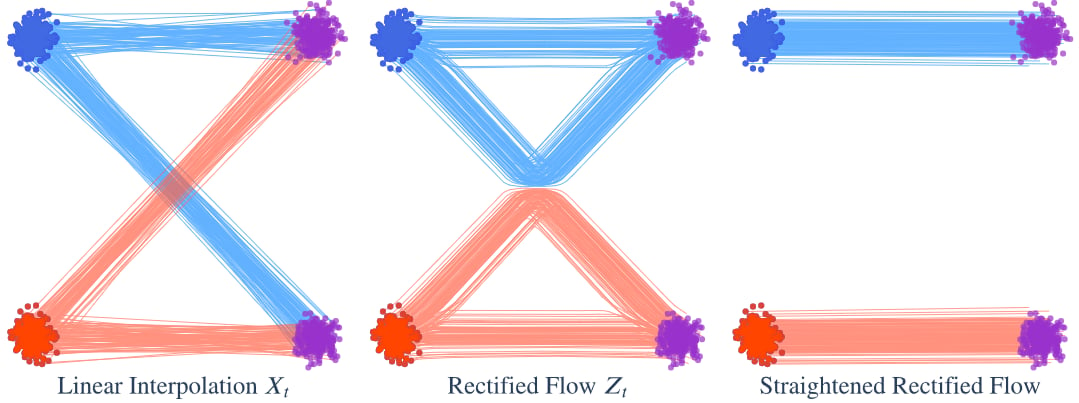
原本
论文证明了对于下面的 “直线程度” 度量
满足
随
Reflow 其实就是从 OT 角度解释了先前的时间步蒸馏技巧。常见的预训练模型都没有做 Reflow 蒸馏。
Stochastic Interpolants
WIP.
Diffusion
DDPM 和 DDIM 也有很多种推导的方法,下面摘自 苏神博客 中贝叶斯角度的推导,比较接近 DDIM 论文的推导方式。
DDPM
与 GAN 类似,DDPM 模型将生成定义为将一个随机噪声
其中
其中
注意到如果规定
于是
将
也可以写成
只要
然而,
代入
使用此分布采样
进而得到完整的损失函数
最后,用
并进一步得到 DDPM 的迭代采样公式
其中
在 DDPM 原始的实验中,
DDIM
DDIM(Denoising Diffusion Implicit Models)模型在 DDPM 的基础上进一步推导了采样公式,发展了允许跳过时间步和确定性的采样方法,并允许将扩散模型的采样过程与常微分方程和随机微分方程的求解算法结合起来。本节将介绍 DDIM 的主要推导过程和结论。
注意到在 DDPM 的神经网络
则关于
比较上式与
是关于
公式中的三项可分别视作从
另外,在推导
这实质上允许了以任意的时间步序列
Flow 与 DDIM 联系
三篇提出 Flow 模型的论文都分析了 DDIM 模型在 Flow 框架中的地位。在 FM 论文中,可以使用 DDIM 的均值和方差特性来设计条件速度场
后续有一些博客文章整理和可视化了 Flow Matching 和 DDIM 的关系:
- Diffusion Meets Flow Matching - DeepMind
- Let us Flow Together - UT Austin
Flow 和 Diffusion 的关系可以从重参数化、插值方式和 ODE/SDE 的角度来讨论。
重参数化
此处重参数化指的是在模型中神经网络预测的对象不一样。DDIM 采样公式可以写成以下简单形式:
其中
Flow 模型的采样公式为
神经网络预测速度场
其中
表中
此处跳过 DeepMind 博客中关于采样时重参数化和缩放的讨论,在下一小节讨论插值时会提到。
考虑重参数化对训练过程的影响。常用的 DDIM 的损失函数为
其中
在 Stable Diffusion 3 中,CFM 训练的损失函数中也引入了人为选择的时间步权重函数:
为了便于比较,我们把这些损失函数都重参数化使用
| 说明 | ||
|---|---|---|
| 在两种情形之间取得平衡 |
表明神经网络的不同预测对象意味着在预测
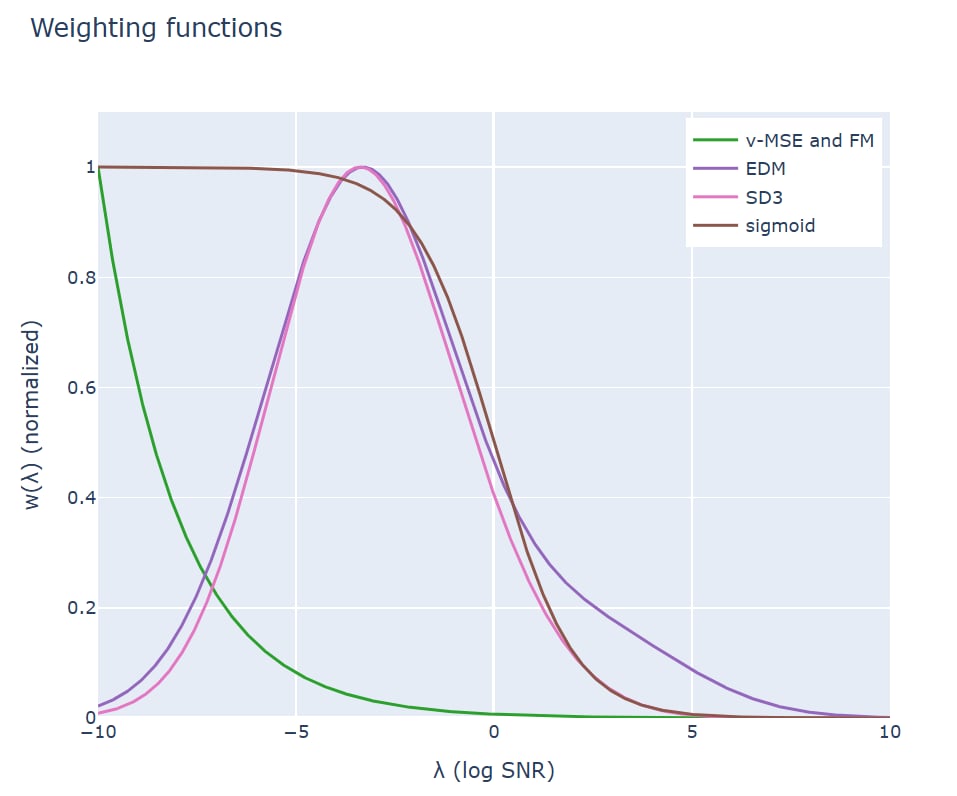
结合考虑重参数化的影响,SD3 的损失函数时间步权重实际上很接近 EDM.
插值
Rectified Flow 使用线性插值构建
而 DDIM 和其他概率流 ODE 可以写成更通用的仿射插值形式
具体来说, 时间步均匀的球面插值可以写成
而 DDIM 相当于在球面插值的基础上缩放了时间步
看起来在训练之前就必须选择一种插值形式,并且在采样时也必须使用同样的插值形式,因为速度场
实际上,在一个很宽松的条件下,可以证明,使用任何插值形式训练并使用不同的插值形式采样,使用相同的训练集数据对

以下是一种感性的理解方式:如果两种插值过程能以一种可微的方式互相变换,意味着插值的轨迹也可以按照相同的方式互相变换。考虑两条相交的
形式化来说, 对于两条插值路径
并且
则称其为逐点可变换的. 如果两组插值路径
则可证明以下结论:
和 可以使用同一个映射来变换 和 的 Coupling 相同,即采样结果相同 - 设
和 分别是 和 的速度场,则
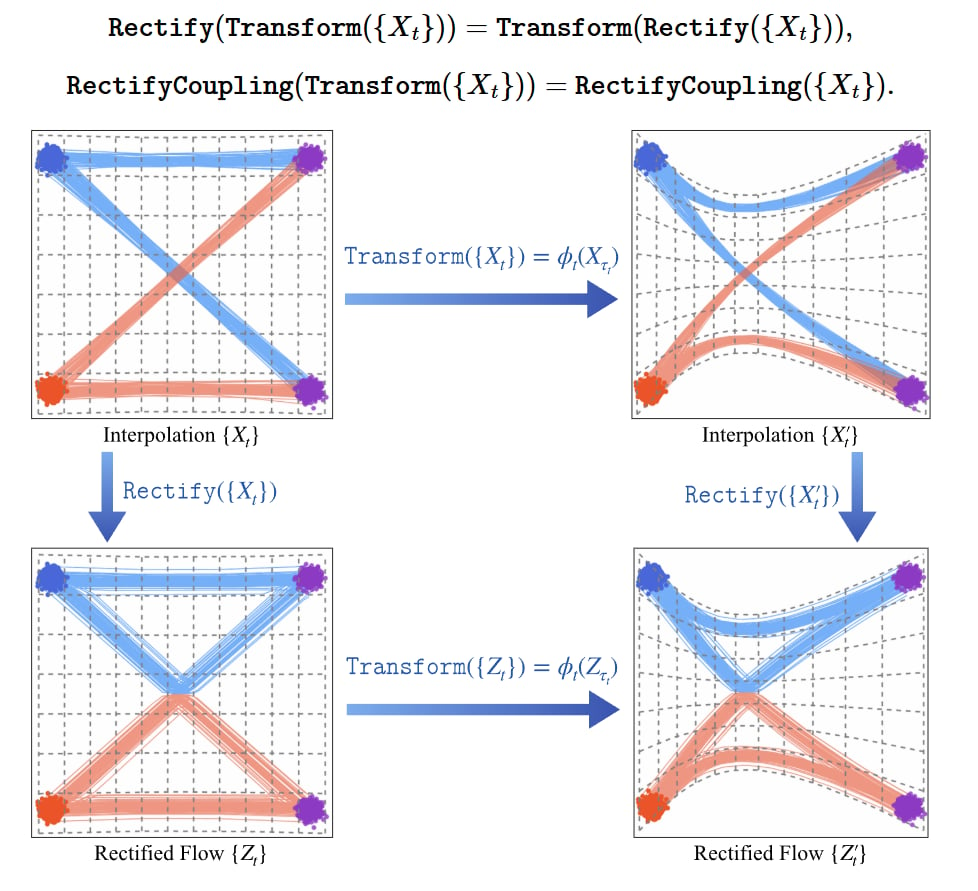
具体对仿射插值 (直线, 球面, DDIM) 来说: 对于两种仿射插值轨迹
其中
对于实际使用的
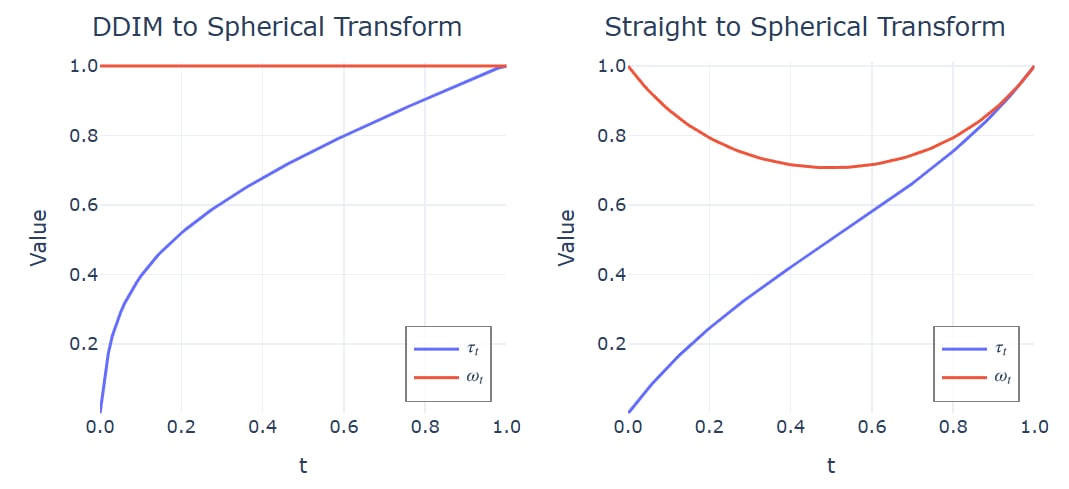
进一步得到适用于仿射变换的速度场变换公式
从直线插值
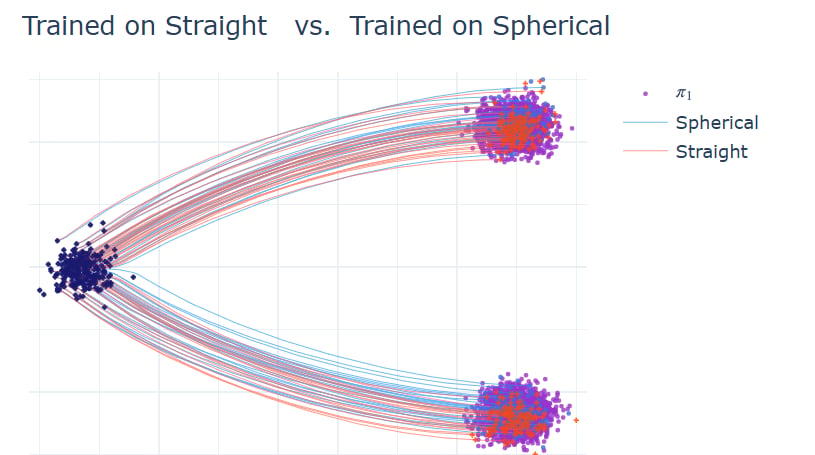
采样时使用不同插值方式得到相同结果
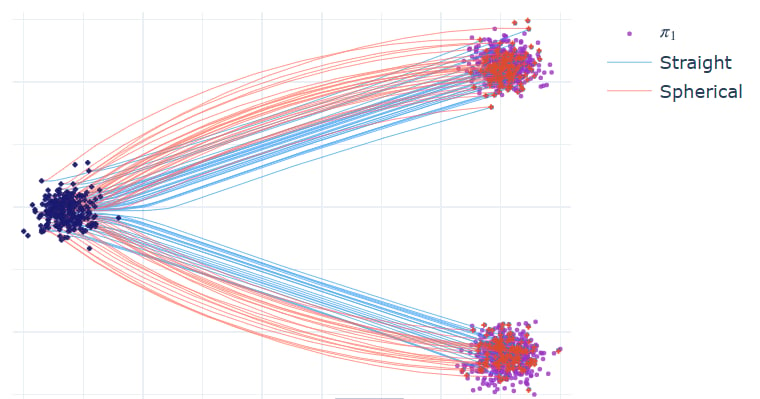
这个演示实验在训练时使用线性插值, 但在采样时使用了按照
看起来直线插值的路径并不直? 首先是因为 Rectify 过程本身就不会产生直线轨迹,
减少时间步后不同插值方法的差异
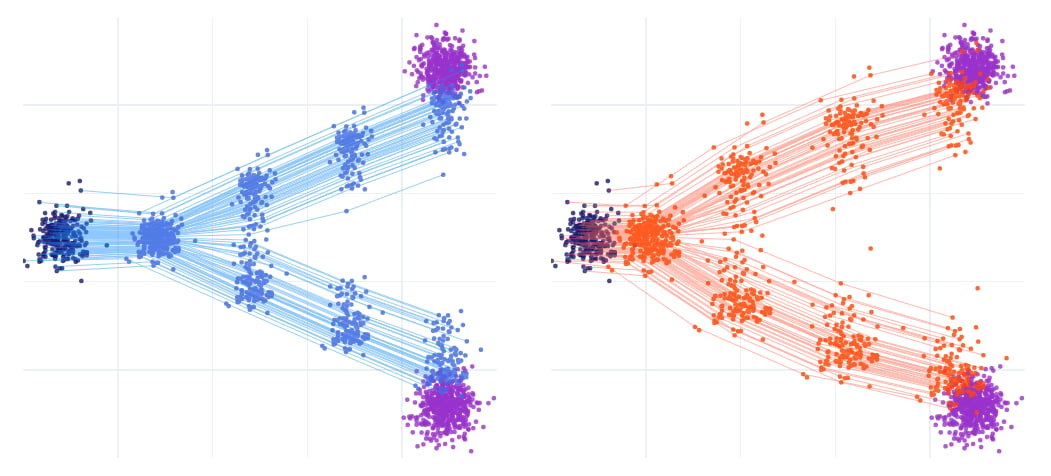
尽管理论上经过正确的速度场变换, 不同插值方式应该得到相同的结果, 然而实际应用中由于采样步数有限, ODE 离散化带来的误差会导致采样结果存在差异. 上图为仅使用 4 步 Euler 法采样的结果, 两种插值方式表现出了明显的区别.
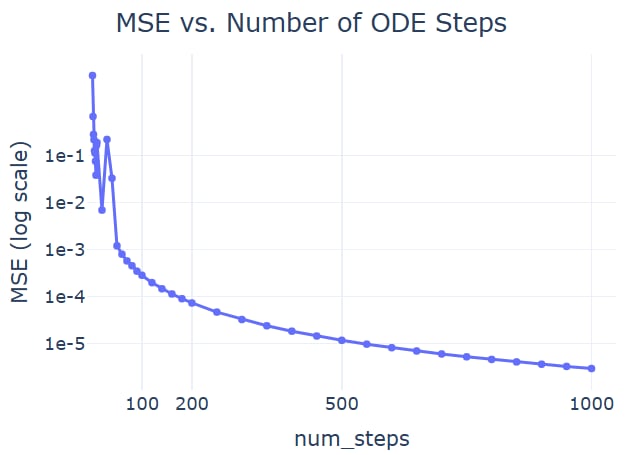
增加 Euler 法的步数, 两者差异逐渐收敛到零.

DeepMind 博客 中展示 DDIM 和 Flow Matching 采样时差异的实验也是只使用 6 步 Euler 法采样. 上面的分析表明此处展示的区别主要是由步数少造成的, 而不是本质上训练目标的不同.
插值方式的选择影响训练
如上一节介绍的, 训练时不同的插值方式相当于施加了时间步权重. 如果手动增加时间步权重项抵消插值方式不同的影响, 同时使用正确的方式在采样时变换速度场, 则可以得到相近的采样结果.
ODE / SDE
结合之前的讨论, 已经可将 Rectified Flow 的速度场通过仿射缩放变换为 DDIM 的速度场, 再重参数化成常见的 DDIM ODE 采样公式
Flow Matching 的 ODE 形式已经很美好了:
朗之万动力学
这是朗之万动力学的随机微分方程, 描述随机过程
- 漂移项
是方程的确定性部分, 表示系统受到一个与概率密度 有关的力的影响. 指向概率密度 增加的方向. 是参数控制漂移的幅度. - 扩散项
是方程的随机部分, 是一个布朗运动. 是一个服从正态分布的随机噪声, 是控制噪声强度的参数. 加入随机性有助于系统脱离局部机制, 收敛到全局高概率区域.
这个朗之万动力学过程满足 Fokker-Planck 方程
因此满足平稳性条件, 即
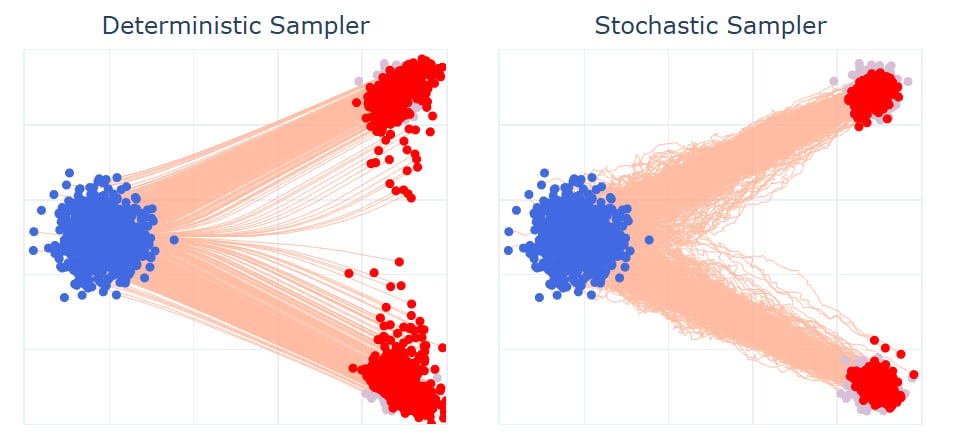
在标准的 RF ODE 中加入朗之万动力学项
其中
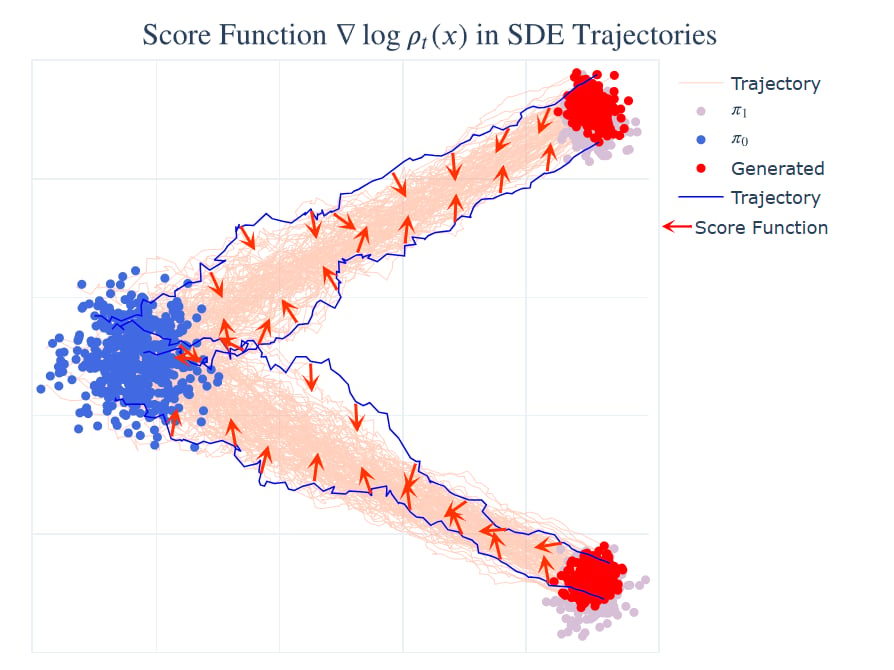
下面的实验中训练时速度场
为了写出
代入 RF 速度场的定义式
可以得到
代入
使用线性插值
而取
增加噪声尺度的效果
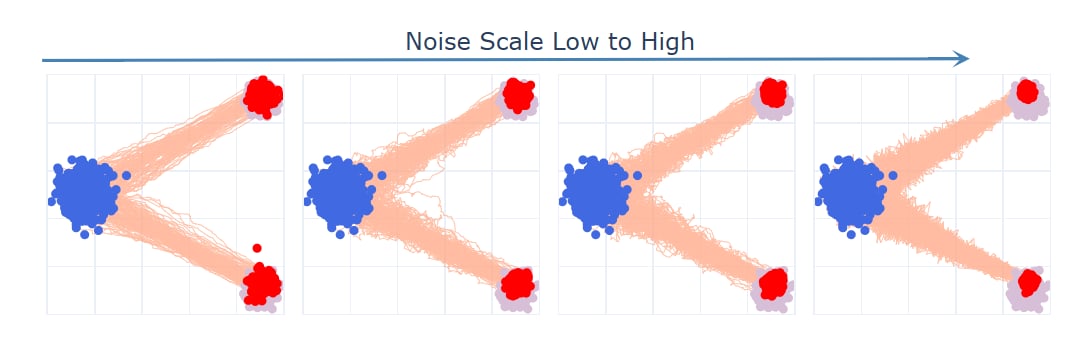
反直觉的结果是增加噪声尺度

EDM 论文 的附录 E 中观察到了类似的现象, 但没有给出原因. 这里的分析也不够充分说明 “过度集中” 现象发生的原因,可能与神经网咯拟合速度场的误差有关。
Qiang Liu 组的最新工作 尝试解决这个问题。






