强化学习作业 3

Problem 1

对应于从 S 出发的单源最短路问题。容易得到一种最优策略
最优策略不唯一。
Problem 2

构建
1 | n = 4; |
1 | pfunc[a_, s_, t_] := Switch[a, |
价值迭代算法
1 | valueIteration[r_, p_, v0_, \[Epsilon]_, \[Gamma]_] := |
运行算法,得到输出
1 | v = valueIteration[r, p, ConstantArray[0, n m] , 0.1, 1] |
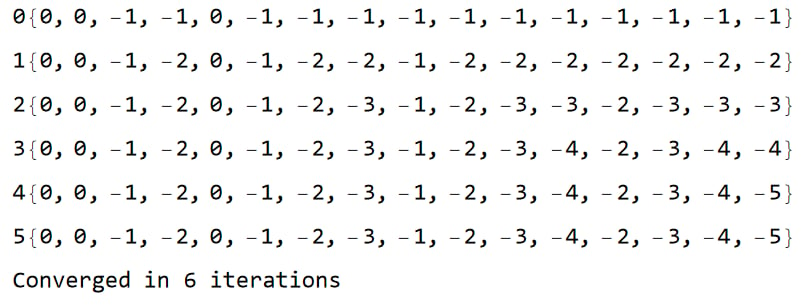
贪心选择策略
1 | greedyPolicy[r_, p_, v_, \[Gamma]_] := |
运行了 6 轮
第三轮得到的价值表为
{0,0,-1,-2,0,-1,-2,-3,-1,-2,-3,-3,-2,-3,-3,-3}, 对应的策略为最后得到的价值表为
{0,0,-1,-2,0,-1,-2,-3,-1,-2,-3,-4,-2,-3,-4,-5}最后的最佳策略为
与第一问得到的结果几乎是一致的。


Problem 3

1 | policyIteration[r_, p_, \[Pi]0_, \[Epsilon]_, \[Gamma]_, n_] := |
1 | policyIteration[r, p, ConstantArray[1, n m], 0.1, 1, 2] |
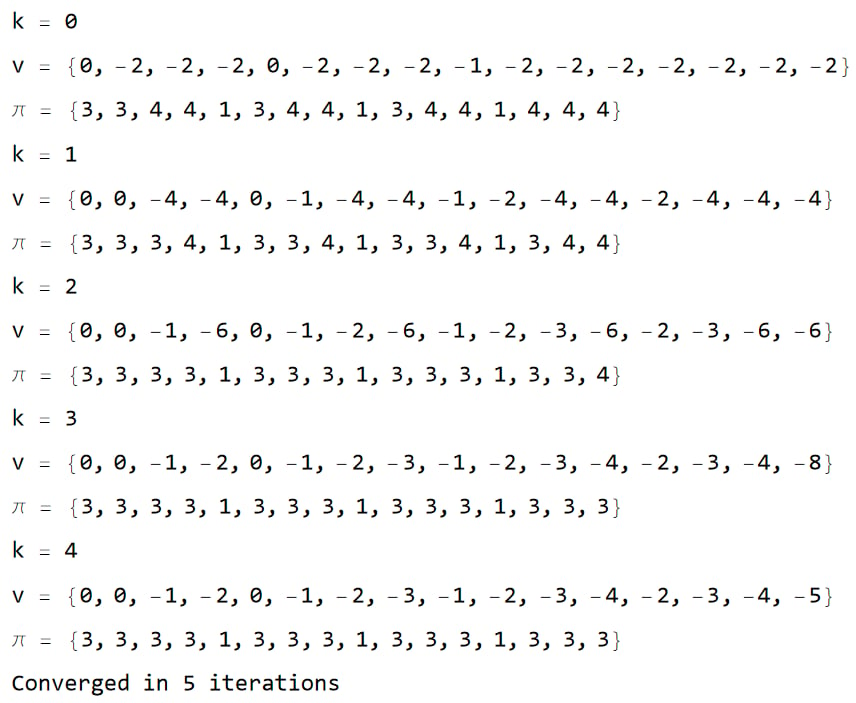
需要 5 轮收敛
收敛得到的策略与 VI 一致。
收敛得到的价值表与 VI 一致。
第三轮结束时得到的价值表
{0,0,-1,-6,0,-1,-2,-6,-1,-2,-3,-6,-2,-3,-6,-6}, 对应策略表

Problem 4

注意到 VI 可以等价为
很难比较两种做法的效率,VI 的迭代过程虽然更简单,但可能面临精确步长法相比于共轭梯度法的问题,导致总共的迭代次数比 PI 更多。






