强化学习作业 5
Problem 1 - 动作价值的学习与 Off-Policy
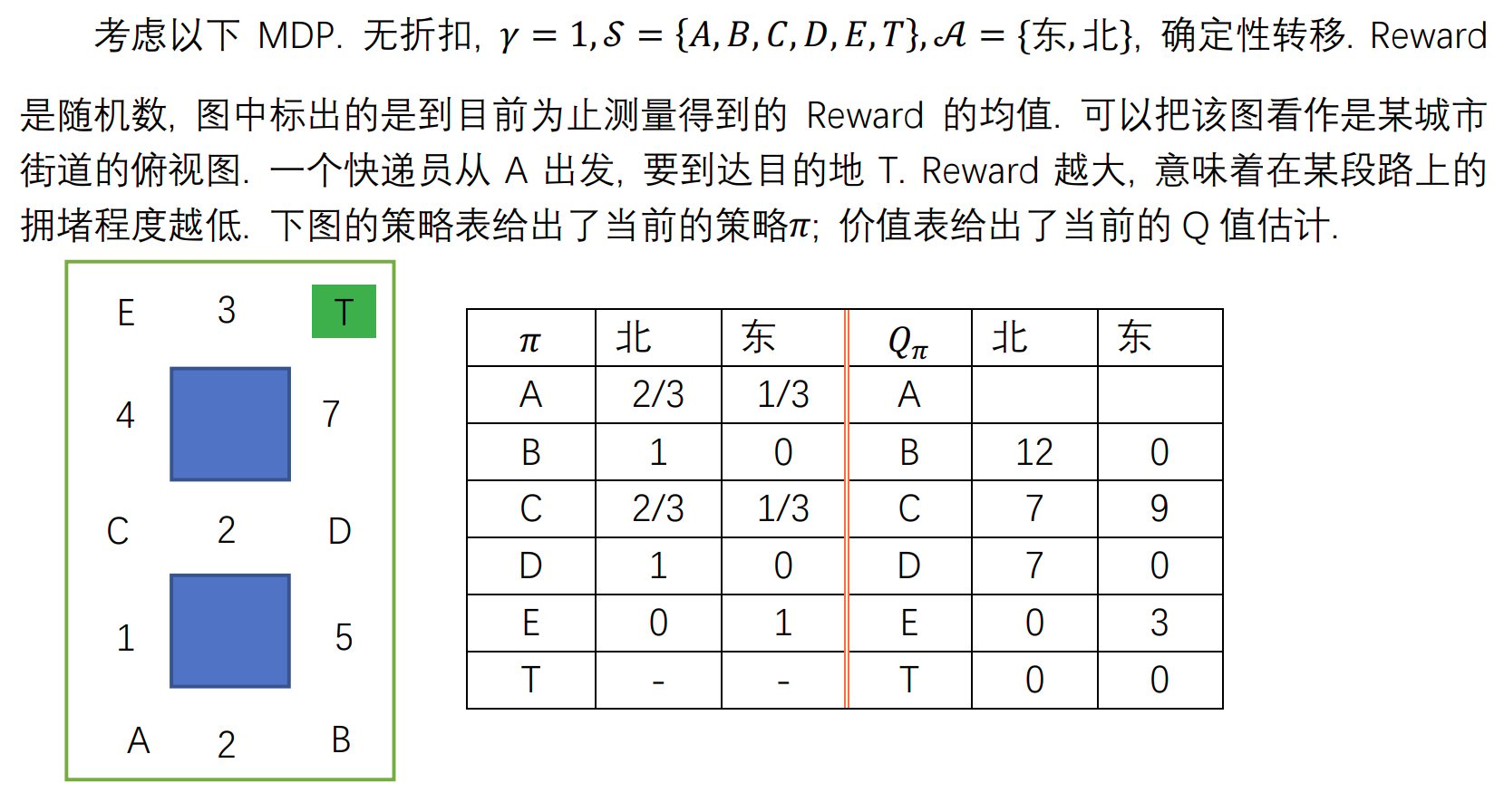
Question 1

Question 2

对于
对于
对于
Question 3

对于
对于
对于
Question 4


Question 5

因为状态价值直接与策略有关。在 Bellman 方程中,状态价值需要用策略对下一步的状态价值加权求和,
Problem 2 - Q-Learning 算法的收敛性


对于
对于
对于
对于
对于
对于
因为状态价值直接与策略有关。在 Bellman 方程中,状态价值需要用策略对下一步的状态价值加权求和,






