强化学习作业 7
Problem 1




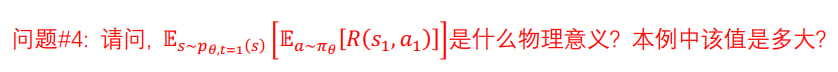
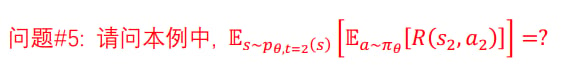

Problem 2

后向 TD(λ) 里的资格迹累积并衰减某个状态
后向 TD(λ) 通过资格迹来利用现在的信息更新“过去”的状态价值。后向 GAE 里资格迹没有直接的像 TD 那样用现在的信息来更改一个现在没有直接关联的值,但也要求在求梯度的过程中,导致现在的优势函数归因到过去的动作(策略)上,这个“归因到过去”的语义是类似的。
Problem 3

如果这里的 LM 算法是指 Levenberg-Marquardt 算法,那么这个算法是用来求解非线性最小二乘问题的。这个方法是通过将 Gauss-Newton 方法和梯度下降方法结合起来,通过引入一个参数
其中
解得步长为
注意到
Problem 4
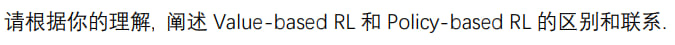
从定义上看,Value-based RL 指的是通过学习值函数,学习每个状态的价值,再通过贪心方法得到贪心策略的方法,策略作为贪心的 argmax 的结果是具有确定性的。而 Policy-based RL 则跳过了学习值函数这一步,直接学习策略,因此有可能表示一个非确定性的策略。
在使用显式的表格法的时候,两种模式是容易区分的;而在使用隐式的函数近似的时候,这两种方法的区别就不明显了。如果使用隐式的方法来表示状态、动作的价值(比如 DDPG 试图解决的连续动作的情况),这个时候从状态价值贪心地得到策略就不是那么容易了,导出的策略也可以是非确定性的,于是就模糊了 Value-based 和 Policy-based 的边界。另一方面,存在一些方法,比如 AlphaZero 能同时学习策略和价值。AlphaZero 的神经网络同时给出了状态下价值和策略的估计,策略用于拓展搜索树,估计的价值用于 Backup 从而改善后续的搜索策略。这种方法可以看作是 Value-based 和 Policy-based 的结合,也是一种混合方法。于是,Value-based 和 Policy-based RL 并不是对立的,而是一种方法的不同侧重点,实际中的方法可能会同时使用两种方法的优点。






